Cleaning up this blog with AI
It has been several years since I wrote a post on this blog. Part of this is not really feeling like something I have worth articulating here (though that is changing a little lately), but a bigger part is that it felt like a huge amount of work to get this blog into a state where I didn’t feel like it was full of outdated articles and junk metadata. Something a little more current.
Well, we now have a tool that all of us can use to help ease this kind of menial work: AI. So, using ChatGPT, I cleaned house and wrote this article to cover how I did it.
First, after reviewing the articles I had, and considering the long gap I’ve had since last writing, I wanted to figure out what to do with articles I didn’t consider relevant or articles that no longer matched my writing style, or synced with my current opinions and thoughts. So I sent this prompt to ChatGPT:
what should i do for a technical blog where i have a bunch of posts from pre-2019 that aren’t very relevant anymore technically, or don’t match the tone of my writing anymore, or that i find not useful for a variety of other reasons. should i delete the posts? will google punish me if i do? should i archive them in some way and start fresh? not sure…
It waffled on a bit, but at the core of it the recommendation was this:
- Keep & refresh posts with value
- Archive or add disclaimers for posts with historical interest but outdated info
- Delete and redirect or respond with 410 Gone for those with no value, no traffic, no links
I had already been doing this a little with a “deprecation” warning on extremely old and irrelevant posts like this one I wrote in 2012, but this time I wanted to do this for a lot more of my articles. I then asked ChatGPT for a recommendation on the process behind this to see if we were on the same page, and we were. I don’t need to paste in what it said here, it was quite long but pretty much repeated the above.
Next, I exported the last 3 years of traffic for this blog from Google Analytics, ordered by view count, including the title and other information, then asked this, attaching the Google Sheet for context for ChatGPT, then gave it this prompt:
build me a spreadsheet template. also look through the list of my posts and identify ones where it’s likely i should delete/archive it and not show it on the main list of blog posts etc. Here are the view stats for the past 3 years attached as a google sheet. also dont just take into account views but based on title/content on whether it should be outdated like you found with angular earlier
At first it just did a light once-over and gave me a few recommendations on selected posts. However, what I really wanted here was for it to give me a full CSV with a recommendation on what to do for every post on my blog. It delivered, but unfortunately…here it got a bit confused. The recommendations often didn’t match the URLs, and the recommendations weren’t really in depth.
Here ChatGPT started to go off the rails a bit…I kept asking it to do different things with the information, giving it less source information in the spreadsheet I provided, and asked it to go scrape every article so it could give me a proper informed recommendation. There was a lot of “Thinking…” and back and forth. Eventually, after some context resets, I got it to output a spreadsheet like this with some basic recommendation and reasoning:
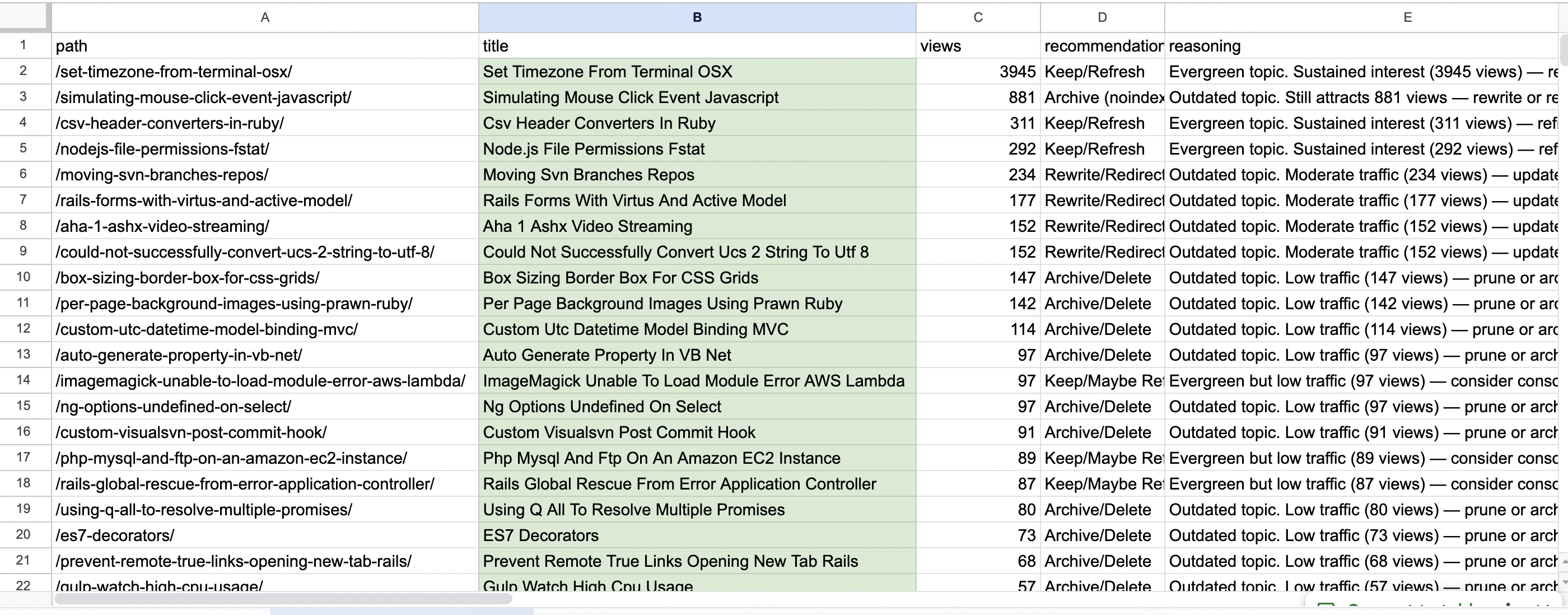
It’s not perfect, but it gave me a solid enough base to go on. It’s really important to know when to call it quits with an AI chat, where it starts to lose its marbles and extra instructions and context aren’t helping. Often starting a new chat and seeding it with initial data from the old one is all you need to get things moving again.
Working through the spreadsheet
The next step I took was to go through this list one by one, look at the recommendation and reasoning, and alter the source post in markdown. Sometimes I didn’t agree with the recommendation, or thought it overly harsh. Call me sentimental but I didn’t want to delete half my posts. So, most of the time, I went and added a deprecation with a liquid template include like so:
1
{% include deprecated.html message="There are probably better ways to do this now, especially if you are using https://playwright.dev/ . This article also references many deprecated browser APIs. Leaving this as a historical curiosity." cssclass="deprecated" %}
For many of the articles, I knew there was likely a better way to do something, especially in cases for articles 5-10+ years old, but I didn’t want to spend too much time researching it. So, I fed certain articles here into ChatGPT (it’s already surely ingested them, so no harm really) and asked it for advice on anything that should be tweaked, or in some cases I asked it to recommend a deprecation warning to place at the top of the article.
For example for Global rescue_from error in Rails application_controller, it gave me these recommendations:

And so I went through and made some alterations, but I didn’t add a deprecation. In other cases, I did ask it for a deprecation, for longer articles giving it the URL directly. For example for Custom time formats in rails, I asked it for a deprecation if necessary. Of course it spat out an overly verbose one:

So I just condensed it down to this:
1
{% include deprecated.html message="In 2025 this still works in Rails, but it is likely better to rely on other methods like defining time formats in the Rails I18n system yaml files and using <code>I18n.l</code> rather than <code>Time.to_fs(:format)</code>" cssclass="deprecated" %}
Of course, with its recommendations I did go and double check with a brief bit of research to make sure it wasn’t pulling my leg, or giving outdated advice itself, and it was generally accurate. This system helped a lot for programming languages I haven’t touched or kept up with, like C#, for things like Sharing dynamic objects between assemblies in C#
Fixing encoding issues
Another issue I found was with encoding in many of the markdown posts. Maybe this was a relic of the move from wordpress, and it didn’t really affect rendering, but it made the markdown source very ugly, especially within source code blocks. So I asked ChatGPT to give me a script to fix this across all the markdown files. It is perfect for boring manual labour like this:
i have an article with lots of encoded characters like
We’vein vim markdown, can you write me some script or something to fix all of them? another example is also replacing^Mchars and12–15
Here is the script it spat out. Is it nice python? I don’t know and I don’t care, but when I ran it it worked just fine, so problem solved:
1
2
3
4
5
6
7
8
9
10
11
#!/usr/bin/env python3
import html, pathlib
for p in pathlib.Path(".").rglob("*.md"):
raw = p.read_bytes()
# normalize line endings: CRLF/CR -> LF (removes ^M)
raw = raw.replace(b"\r\n", b"\n").replace(b"\r", b"\n")
text = raw.decode("utf-8", errors="replace")
text = html.unescape(text) # decode & ’ etc.
p.write_text(text, encoding="utf-8")
print(f"fixed {p}")
I could have probably told it to do it in ruby so I could read it a bit better, but really I was using AI to generate me a hammer so I could smash an annoying nail with it, so it didn’t really matter.
Deleting old junk metadata
There was also a bunch of ancient metadata in the markdown source. Like for example these mashsb attributes, which are from a Wordpress social media sharing tool that is no longer in use, and which is totally irrelevant for Jekyll anyway:
1
2
3
4
5
6
mashsb_timestamp:
- 1464957941
mashsb_shares:
- 0
mashsb_jsonshares:
- '{"total":0}'
Again, I asked ChatGPT. At first I asked it for some neovim script, but I kept having weird issues with Lualine with the code it provided, so I asked it to just do a unix script of some kind instead, and it ended up using sed, which worked great:
1
2
3
sed -i '' -e '/^mashsb_timestamp:/,+1d' \
-e '/^mashsb_shares:/,+1d' \
-e '/^mashsb_jsonshares:/,+1d' *.md
There were several different chunks of metadata like this – I didn’t need to use AI more, I just modified the original script:
1
sed -i '' -e '/^guid:/d' *.md
Or this:
1
sed -i '' -e '/^iconcategory:/,+1d' *.md
I could have eventually gotten there without AI, but who really wants to memorize a bunch of sed syntax?
Excluding posts from the Jekyll feed based on metadata
The next thing I wanted to do, which is related to the following section of this article, is hide certain articles from a) the main feed of this blog and b) in certain cases, where I will be redirecting with a 410 Gone, from the archive page. I knew there was a way to do this in Jekyll, but couldn’t be bothered to figure it out myself (omitted the code block I sent to ChatGPT):
i want to change for post in paginator.posts to only get a subset of posts, i.e. not ones with a certain front matter attribute, how can i do this?
I forgot that all yaml front matter metadata for Jekyll is attached to post, so I could just do something like this:
1
2
3
4
5
{% for post in paginator.posts %}
{% unless post.exclude_from_feed %}
<!-- post content here -->
{% endunless %}
{% endfor %}
On both the main post feed and on the archive page. Then, I went and added exclude_from_feed: true and exclude_from_archive: true to the relevant posts.
Figuring out how to respond with 410 Gone for irrelevant posts
In the first step, ChatGPT recommended responding with 410 Gone for “deleted” posts. This code is defined by MDN like so:
The HTTP 410 Gone client error response status code indicates that the target resource is no longer available at the origin server and that this condition is likely to be permanent. A 410 response is cacheable by default.
Clients should not repeat requests for resources that return a 410 response, and website owners should remove or replace links that return this code.
Whereas a 404 can indicate that the condition of the missing article is only temporary, and 301 redirects to a new location, which in my case was not necessary. I wanted these posts to no longer exist when Google’s little crawler bots go poking around for it.
Naturally I didn’t have a clue how to do this with Jekyll, and I couldn’t even remember the server that was running for my blog’s requests on the DigitalOcean droplet. First I asked ChatGPT:
is there a way to serve 410 gone for certain jekyll blog posts
It gave me a ton of different ways to do it based on hosting provider. Then, I sheepishly asked:
im pretty sure i use nginx on a digitalocean droplet, how can i check if nginx is being used / is running
And it gave me the most obvious answer in the world which I definitely should have thought of straight away. Sometimes, when you are set on using a tool…you use that tool instead of the more obvious method in front of you.
ps aux grep nginx
So yes I was indeed running nginx. Knowing that I was running nginx, ChatGPT gave me several great options on how I could use it to serve 410 Gone on certain URLs:
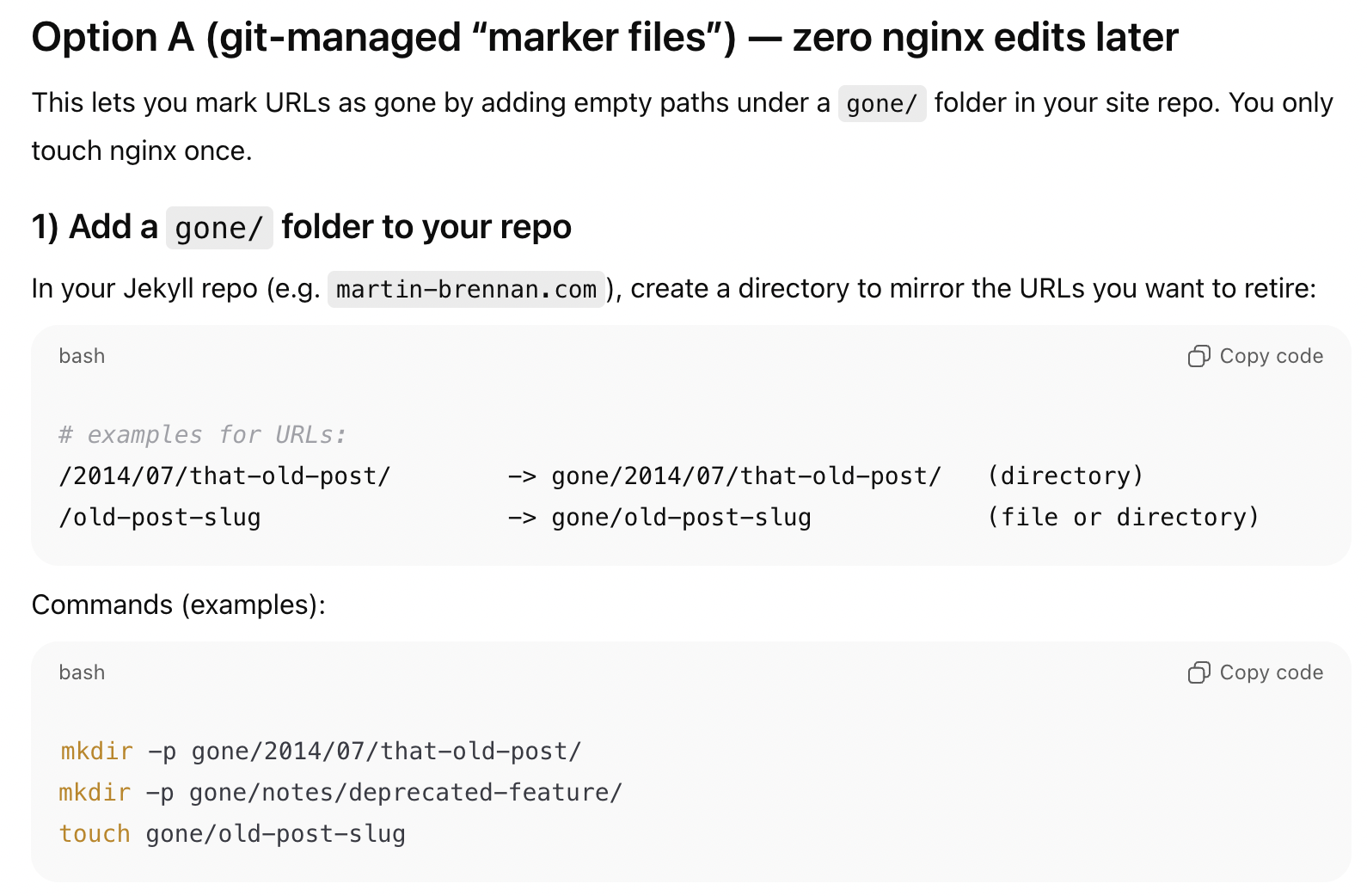
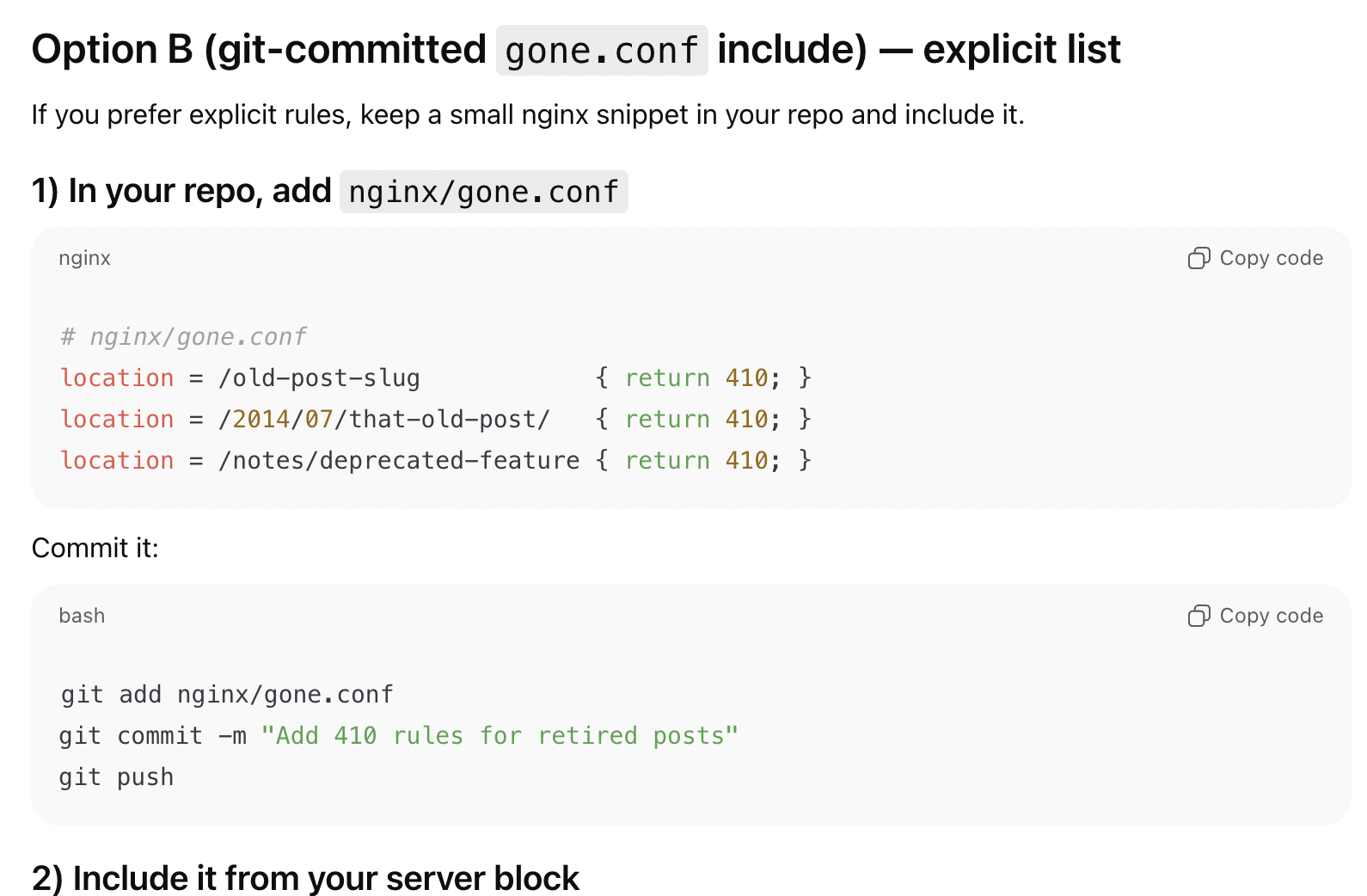
I wanted it to be super easy, and I wanted it to be easy to do via git. So, I chose the second option, where I could commit a gone.conf file to the repo, and then read it from nginx:
1
2
3
4
5
server {
# ...
include /var/www/your-site/current/nginx/gone.conf;
# ...
}
The only downside is that I will have to log in and restart nginx whenever I add an entry here. However, I won’t be doing it often after this initial batch, so it’s no big deal. This worked perfectly! I even had AI generate a script I could run to extract the permalinks from all the posts I marked as hide from archive and morph them into the nginx config format I needed:
1
2
3
4
5
location = /a-baseline-for-frontend-developers-by-rebecca-murphey/ { return 410; }
location = /callback-hell/ { return 410; }
location = /creating-share-buttons-with-just-urls/ { return 410; }
location = /goodbye-requirejs-hello-browserify/ { return 410; }
... and so on
Removing ads
This isn’t strictly related to AI, but as I was working on this blog I noticed how awful the experience felt with ads on. I had way too many, they got in the way, they were irrelevant, and what’s worse is that they didn’t serve a purpose – I haven’t made any money from this blog in years, and even when I did it was $100 every few years. Not really worth it for a worse experience.
So, I ripped them out, and it feels a lot nicer. Maybe at some point in future I may introduce them again, but not until there is actually a level of traffic that makes it worth it.
What’s next?
I plan on doing another refresh of this blog’s styling and layout. I want to use AI to completely rework the CSS of this site, along with the HTML templates. I have no idea what a lot of the CSS is doing or where it’s located, and navigating it is trying to traverse the warp without a Gellar field. Maybe I will use something like tailwind, but I’m not quite decided on that. I have never addressed the CSS mess I have here, since it seems such a daunting task, but with AI maybe it will become bearable.
I have already started using ChatGPT to find me examples of other technical blogs from staff engineers that I can draw inspiration from, but with varying levels of success thusfar. Not exactly sure where I am going yet, but I want things to have a more up-to-date feel, and I want code blocks and syntax highlighting to feel a lot better. Maybe present images better with captions and lightboxing. We will see where I end up…